This repository was archived by the owner on Apr 12, 2024. It is now read-only.
Buffer sendResponseMessage and its variant methods #52
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
|
|
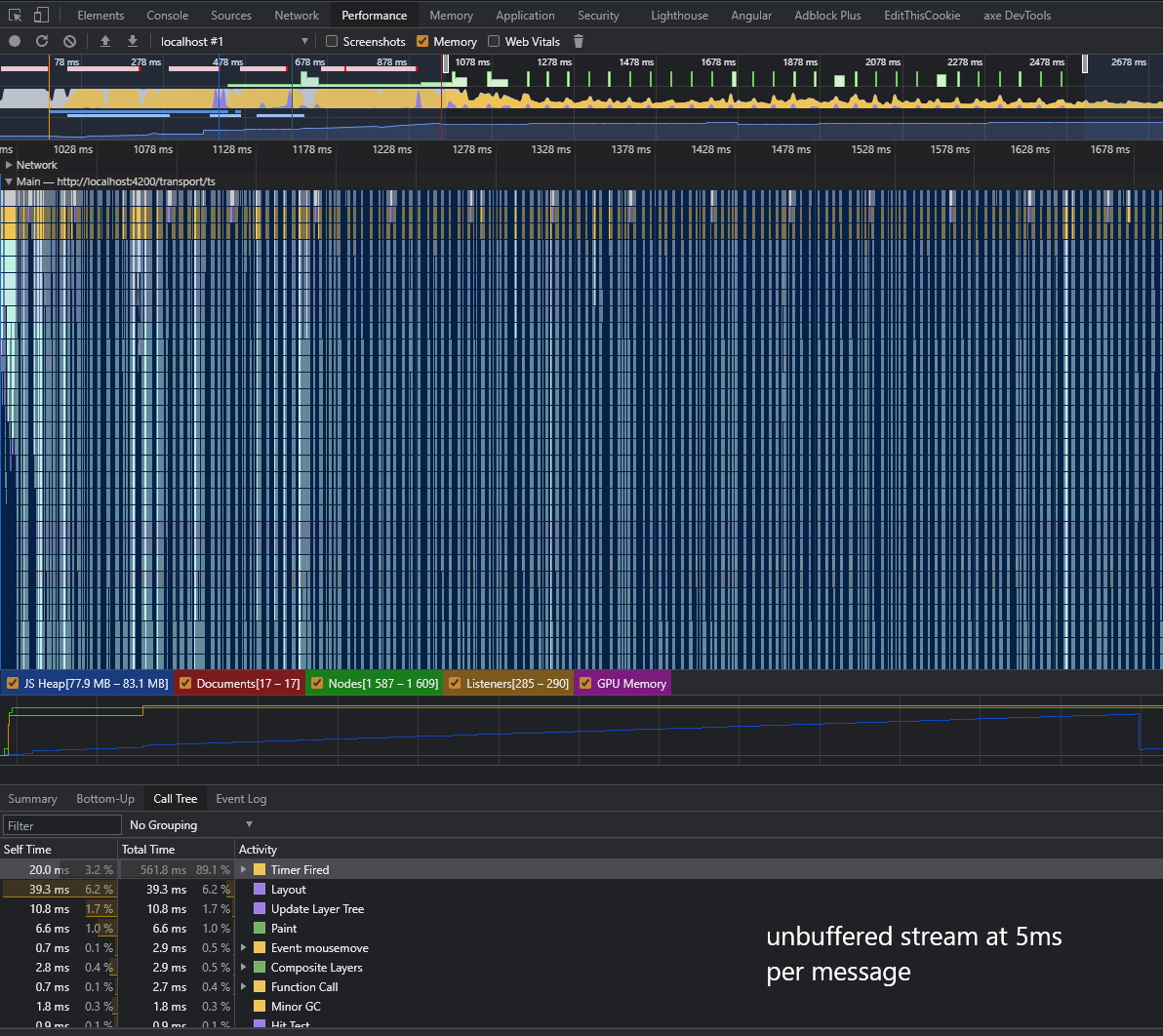

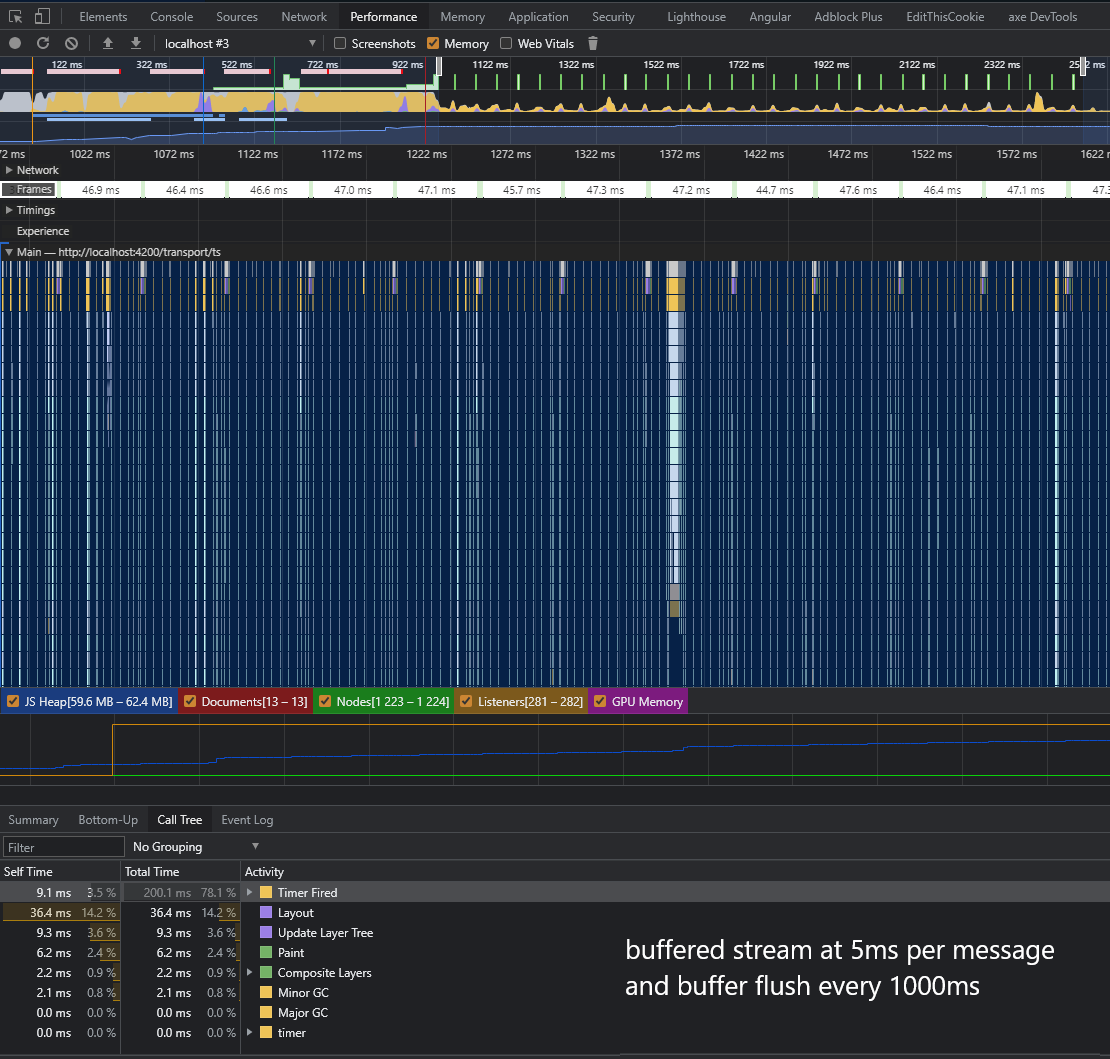
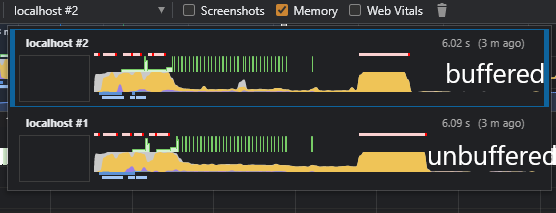
Internal testing on VMware Cloud UI revealed that there are certain conditions that could impact the performance of the Angular change detection system, or any other frontend frameworks that rely on the Event Loop of the JS engine. Currently every message being sent via the `sendResponseMessage()`, `sendResponseMessageWithId()` or `sendResponseMessageWithIdAndVersion()` method is scheduled as a macro task, which means send message logic shares CPU resources with other macro tasks like DOM painting or other event handling. This way of sharing the CPU single thread with other tasks usually is benign enough not to cause much trouble if any. However, if 1) the send message method is called in rapid succesion, and 2) each macro task triggers a compute-intensive task such as a complete re-render of the view like Angular with default change detection strategy does, the UI will experience a significant performance hit that looks like a tight loop that could be observed in the Chrome Inspect Panel. A sensible solution to the problem is to buffer the payload by a certain interval and scheduling the macro tasks by chunks not by every single entry. By doing this it will limit the impact to the CPU because now the change detection will happen only as frequently as the buffer is flushed. See the attached benchmarks for comparisons in CPU utilization. Signed-off-by: Josh Kim <[email protected]>
Signed-off-by: Josh Kim <[email protected]>
0f3793d to
924442c
Compare
Sign up for free
to subscribe to this conversation on GitHub.
Already have an account?
Sign in.
1 participant
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Internal testing on VMware Cloud UI revealed that there are certain
conditions that could impact the performance of the Angular change
detection system, or any other frontend frameworks that rely on the
Event Loop of the JS engine.
Currently every message being sent via the
sendResponseMessage(),sendResponseMessageWithId()orsendResponseMessageWithIdAndVersion()method is scheduled as a macrotask, which means send message logic shares CPU resources with other
macro tasks like DOM painting or other event handling. This way of
sharing the CPU single thread with other tasks usually is benign enough
not to cause much trouble if any.
However, if 1) the send message method is called in rapid succesion,
and 2) each macro task triggers a compute-intensive task such as a
complete re-render of the view like Angular with default change
detection strategy does, the UI will experience a significant
performance hit that looks like a tight loop that could be observed
in the Chrome Inspect Panel.
A sensible solution to the problem is to buffer the payload by a
certain interval and scheduling the macro tasks by chunks not by
every single entry. By doing this it will limit the impact to the
CPU because now the change detection will happen only as frequently
as the buffer is flushed.
See the attached benchmarks for comparisons in CPU utilization.
Signed-off-by: Josh Kim [email protected]