The Objective of the Project is to diagnostically predict whether or not a patient has diabetes based on certain diagnostic measurements in the dataset. All patients are female of age >=21.
In statistics and machine learning, ensemble methods use multiple learning algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone.
K nearest neighbors is a simple algorithm that stores all available cases and classifies new cases based on a similarity measure (e.g., distance functions).
Random forests or random decision forests are an ensemble learning method for classification, regression and other tasks that operate by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes or mean/average prediction of the individual trees.
Logistic Regression, also known as Logit Regression or Logit Model, is a mathematical model used in statistics to estimate (guess) the probability of an event occurring having been given some previous data. Logistic Regression works with binary data, where either the event happens (1) or the event does not happen (0).
Grid search is the process of performing hyper parameter tuning in order to determine the optimal values for a given model. it is difficult to manually change the hyperparameters and fit them on the training data every time. It helps to loop through predefined hyperparameters and fit the estimator (model) on the training set.
- estimator
- params - list of parameters and the range of values for each parameter of the specified estimator. All you need to do is create a dictionary (variable params in my code) that has the hyperparameters as keys and an iterable that holds the options we need to try out.
- cross validation - A cross validation process is performed in order to determine the hyper parameter value set which provides the best accuracy levels. variance problems is dealt with in cross validation.









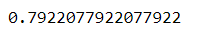
The Score of ensemble model is more than the Individual score of constituent models