这是一个简单的文本分类项目,手动编写朴素贝叶斯算法实现对新闻的分类,同时也调用sklearn测试支持向量机的分类效果。
主要可以分为两大任务 :一是从各大新闻网站爬取新闻信息,二是编写分类算法。
Window10、python3
本项目中使用到的包有:
- 爬虫相关:requests、selenium、bs4
- 分类相关:jieba、pickle、sklearn、seaborn、pandas、numpy、matplotlib、time、os
混合数据集,即部分数据利用爬虫获取,部分使用现有数据集,总共10个类别,具体情况如下:
-
新浪滚动新闻网
https://news.sina.com.cn/roll/#pageid=153&lid=2517&k=&num=50&page
爬取的类别有社会、娱乐、体育(每个类别训练集1500,测试集1000)
-
和讯汽车滚动新闻
http://auto.hexun.com/autoscroll/index-1
爬取的类别有汽车(训练集5000,测试集2000)
-
校园新闻网
爬取的类别有校园(训练集2000,测试集1000)
-
cnews
使用的类别有财经、房产、科技、时政、游戏(每个类别训练集5000,测试集1000)
1.爬虫部分
使用python的BeautifulSoup、selenium库,通过提取User-Agent信息,每次模拟用户打开浏览器进行数据爬取。
2.文本分类
① 首先对文本去除多余的换行和空格,然后使用jieba进行分词,去除停用词,将分词结果用空格隔开,然后单独保存。
② 然后计算TF-IDF,将文本转换成词频矩阵,由于矩阵的维数很大,使用SVD降到10000维,同时保存词频和输出空间,其中输出空间以二进制文件保存。
③ 朴素贝叶斯算法
原理:
条件概率公式:
通过 P(A|B) 求 P(B|A) :
对于给定测试集,计算每个类别的 P(B|A),然后取最大的作为预 测类别,由于 P(A) 是固定的,不影响结果比大小,所以只需要计算先验概率和条件概率。
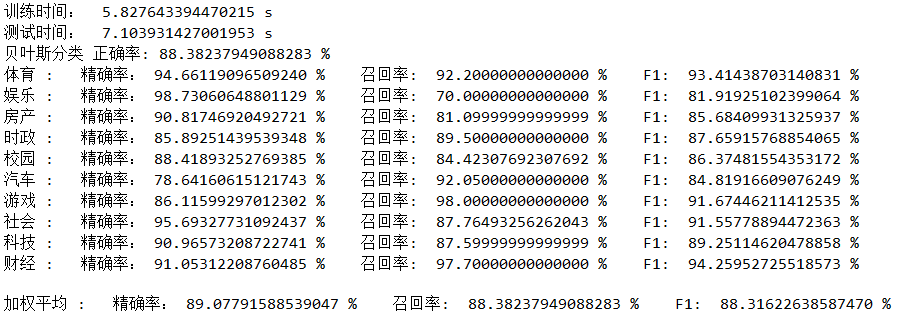
对于预测结果,使用精准率(precision)、召回率(recall)和F1值进行评价。精准率指预测为类别A中预测正确的概率,召回率指真实类别为A中预测正确的概率。
通常一个类别的召回率会影响其他类别的精准率,且对于同一类别,当其精准率较高时,通常召回率偏低。所以需要使用一个综合评价指标来衡量结果,F1是精准率和召回率的调和平均,值越大,预测效果越好。
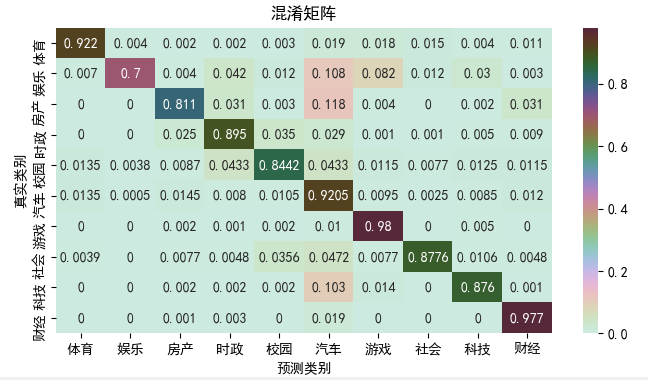
实验结果:
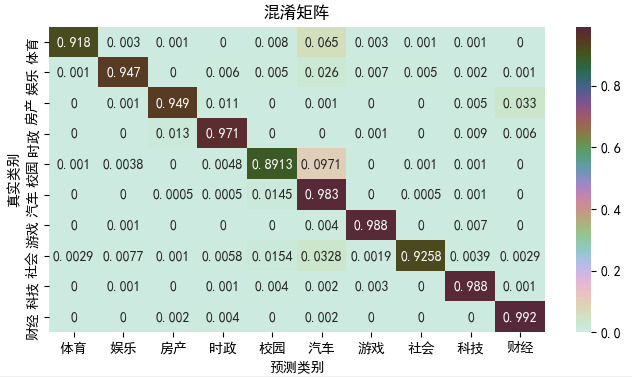
④ 支持向量机算法
实验结果:

ml(分类算法)
——data(训练集)
——data_spider(爬虫下来的训练数据存放位置)
——segResult(训练集分词结果)
——stop(停用词)
——test(测试集)
——test_segResult(测试集分词结果)
——test_spider(爬虫下来的测试数据存放位置)
——class.py(主文件,分类算法)
——test_set.dat(序列化的测试集)
——test_vocabulary.txt(测试集语料)
——testspace.dat(加权后的测试集序列化输出)
——tfidf_vocabulary.txt(加权后的语料)
——tfidfspace.dat(加权后的训练集序列化输出)
——train_set.dat(序列化的训练集)
——train_vocabulary.txt(训练集语料)
——数据源.txt(数据源说明)
spider(爬虫)
——car_data.py(汽车类新闻)
——IT_data.py(IT类新闻)
——school_data.py(校园类新闻)
——sina_data.py(新浪新闻,多个类别)