|
| 1 | +{ |
| 2 | + "cells": [ |
| 3 | + { |
| 4 | + "cell_type": "markdown", |
| 5 | + "metadata": {}, |
| 6 | + "source": [ |
| 7 | + "# Dataframe running SQL query\n", |
| 8 | + "### Dr. Tirthajyoti Sarkar, Fremont, CA 94536\n", |
| 9 | + "### Relational data with flexible, powerful analytics\n", |
| 10 | + "Relational data stores are easy to build and query. Users and developers often prefer writing easy-to-interpret, declarative queries in a human-like readable language such as SQL. However, as data starts increasing in volume and variety, the relational approach does not scale well enough for building Big Data applications and analytical systems. Following are some major challenges.\n", |
| 11 | + "\n", |
| 12 | + "* Dealing with different types and sources of data, which can be structured, semi-structured, and unstructured\n", |
| 13 | + "* Building ETL pipelines to and from various data sources, which may lead to developing a lot of specific custom code, thereby increasing technical debt over time\n", |
| 14 | + "* Having the capability to perform both traditional business intelligence (BI)-based analytics and advanced analytics (machine learning, statistical modeling, etc.), the latter of which is definitely challenging to perform in relational systems\n", |
| 15 | + "\n", |
| 16 | + "We have had success in the domain of Big Data analytics with Hadoop and the MapReduce paradigm. This was powerful, but often slow, and gave users a low-level, procedural programming interface that required people to write a lot of code for even very simple data transformations. However, once Spark was released, it really revolutionized the way Big Data analytics was done with a focus on in-memory computing, fault tolerance, high-level abstractions, and ease of use.\n", |
| 17 | + "\n", |
| 18 | + "From then, several frameworks and systems like Hive, Pig, and Shark (which evolved into Spark SQL) provided rich relational interfaces and declarative querying mechanisms to Big Data stores. The challenge remained that these tools were either relational or procedural-based, and we couldn't have the best of both worlds.\n", |
| 19 | + "\n", |
| 20 | + "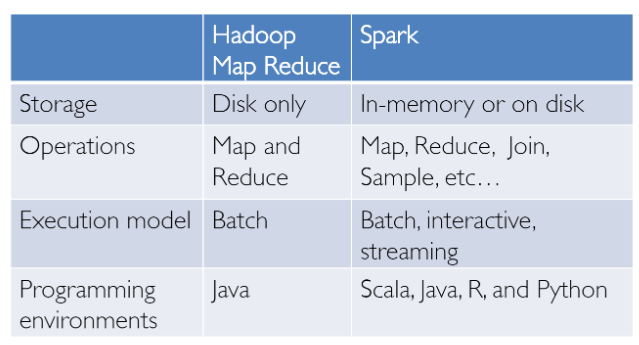\n", |
| 21 | + "\n", |
| 22 | + "However, in the real world, most data and analytical pipelines might involve a combination of relational and procedural code. Forcing users to choose either one ends up complicating things and increasing user efforts in developing, building, and maintaining different applications and systems. Apache Spark SQL builds on the previously mentioned SQL-on-Spark effort called Shark. Instead of forcing users to pick between a relational or a procedural API, Spark SQL tries to enable users to seamlessly intermix the two and perform data querying, retrieval, and analysis at scale on Big Data.\n", |
| 23 | + "\n", |
| 24 | + "### Spark SQL\n", |
| 25 | + "Spark SQL essentially tries to bridge the gap between the two models we mentioned previously—the relational and procedural models.\n", |
| 26 | + "\n", |
| 27 | + "Spark SQL provides a DataFrame API that can perform relational operations on both external data sources and Spark's built-in distributed collections—at scale!\n", |
| 28 | + "\n", |
| 29 | + "To support a wide variety of diverse data sources and algorithms in Big Data, Spark SQL introduces a novel extensible optimizer called Catalyst, which makes it easy to add data sources, optimization rules, and data types for advanced analytics such as machine learning.\n", |
| 30 | + "Essentially, Spark SQL leverages the power of Spark to perform distributed, robust, in-memory computations at massive scale on Big Data. \n", |
| 31 | + "\n", |
| 32 | + "Spark SQL provides state-of-the-art SQL performance and also maintains compatibility with all existing structures and components supported by Apache Hive (a popular Big Data warehouse framework) including data formats, user-defined functions (UDFs), and the metastore. Besides this, it also helps in ingesting a wide variety of data formats from Big Data sources and enterprise data warehouses like JSON, Hive, Parquet, and so on, and performing a combination of relational and procedural operations for more complex, advanced analytics.\n", |
| 33 | + "\n", |
| 34 | + "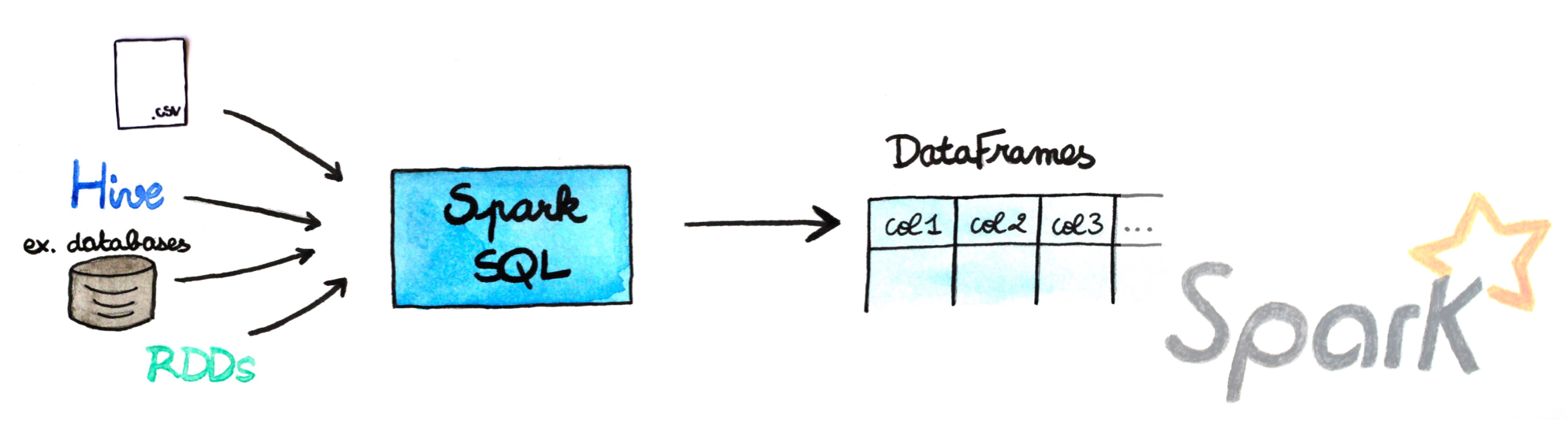\n", |
| 35 | + "\n", |
| 36 | + "### Spark SQL with Dataframe API is fast\n", |
| 37 | + "Spark SQL has been shown to be extremely fast, even comparable to C++ based engines such as Impala.\n", |
| 38 | + "\n", |
| 39 | + "\n", |
| 40 | + "\n", |
| 41 | + "Following graph shows a nice benchmark result of DataFrames vs. RDDs in different languages, which gives an interesting perspective on how optimized DataFrames can be.\n", |
| 42 | + "\n", |
| 43 | + "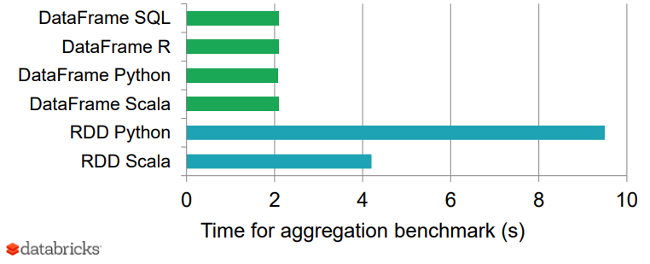\n", |
| 44 | + "\n", |
| 45 | + "Why is Spark SQL so fast and optimized? The reason is because of a new extensible optimizer, **Catalyst**, based on functional programming constructs in Scala.\n", |
| 46 | + "\n", |
| 47 | + "Catalyst's extensible design has two purposes.\n", |
| 48 | + "\n", |
| 49 | + "* Makes it easy to add new optimization techniques and features to Spark SQL, especially to tackle diverse problems around Big Data, semi-structured data, and advanced analytics\n", |
| 50 | + "* Ease of being able to extend the optimizer—for example, by adding data source-specific rules that can push filtering or aggregation into external storage systems or support for new data types\n", |
| 51 | + "\n", |
| 52 | + "Catalyst supports both rule-based and cost-based optimization. While extensible optimizers have been proposed in the past, they have typically required a complex domain-specific language to specify rules. Usually, this leads to having a significant learning curve and maintenance burden. In contrast, Catalyst uses standard features of the Scala programming language, such as pattern-matching, to let developers use the full programming language while still making rules easy to specify.\n", |
| 53 | + "\n", |
| 54 | + "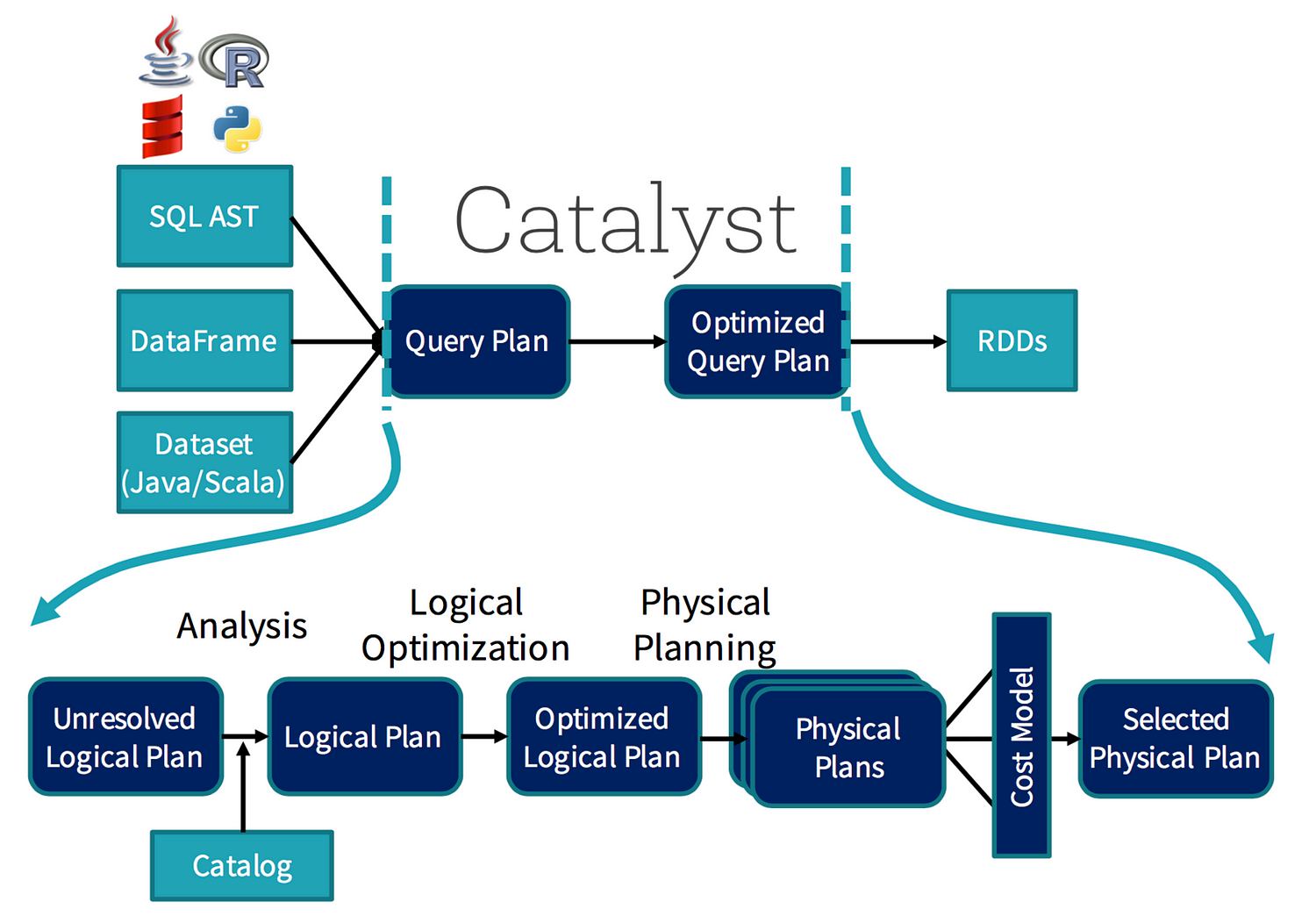" |
| 55 | + ] |
| 56 | + }, |
| 57 | + { |
| 58 | + "cell_type": "markdown", |
| 59 | + "metadata": {}, |
| 60 | + "source": [ |
| 61 | + "### Create a SparkSession and read the a stock price dataset CSV" |
| 62 | + ] |
| 63 | + }, |
| 64 | + { |
| 65 | + "cell_type": "code", |
| 66 | + "execution_count": 1, |
| 67 | + "metadata": {}, |
| 68 | + "outputs": [], |
| 69 | + "source": [ |
| 70 | + "from pyspark import SparkContext as sc\n", |
| 71 | + "from pyspark.sql import SparkSession" |
| 72 | + ] |
| 73 | + }, |
| 74 | + { |
| 75 | + "cell_type": "code", |
| 76 | + "execution_count": 2, |
| 77 | + "metadata": {}, |
| 78 | + "outputs": [], |
| 79 | + "source": [ |
| 80 | + "spark1 = SparkSession.builder.appName('SQL').getOrCreate()" |
| 81 | + ] |
| 82 | + }, |
| 83 | + { |
| 84 | + "cell_type": "code", |
| 85 | + "execution_count": 3, |
| 86 | + "metadata": {}, |
| 87 | + "outputs": [], |
| 88 | + "source": [ |
| 89 | + "df = spark1.read.csv('Data/appl_stock.csv',inferSchema=True,header=True)" |
| 90 | + ] |
| 91 | + }, |
| 92 | + { |
| 93 | + "cell_type": "code", |
| 94 | + "execution_count": 11, |
| 95 | + "metadata": {}, |
| 96 | + "outputs": [ |
| 97 | + { |
| 98 | + "name": "stdout", |
| 99 | + "output_type": "stream", |
| 100 | + "text": [ |
| 101 | + "root\n", |
| 102 | + " |-- Date: timestamp (nullable = true)\n", |
| 103 | + " |-- Open: double (nullable = true)\n", |
| 104 | + " |-- High: double (nullable = true)\n", |
| 105 | + " |-- Low: double (nullable = true)\n", |
| 106 | + " |-- Close: double (nullable = true)\n", |
| 107 | + " |-- Volume: integer (nullable = true)\n", |
| 108 | + " |-- Adj Close: double (nullable = true)\n", |
| 109 | + "\n" |
| 110 | + ] |
| 111 | + } |
| 112 | + ], |
| 113 | + "source": [ |
| 114 | + "df.printSchema()" |
| 115 | + ] |
| 116 | + }, |
| 117 | + { |
| 118 | + "cell_type": "markdown", |
| 119 | + "metadata": {}, |
| 120 | + "source": [ |
| 121 | + "### Create a temporary view" |
| 122 | + ] |
| 123 | + }, |
| 124 | + { |
| 125 | + "cell_type": "code", |
| 126 | + "execution_count": 5, |
| 127 | + "metadata": {}, |
| 128 | + "outputs": [], |
| 129 | + "source": [ |
| 130 | + "df.createOrReplaceTempView('stock')" |
| 131 | + ] |
| 132 | + }, |
| 133 | + { |
| 134 | + "cell_type": "markdown", |
| 135 | + "metadata": {}, |
| 136 | + "source": [ |
| 137 | + "### Now run a simple SQL query directly on this view. It returns a DataFrame." |
| 138 | + ] |
| 139 | + }, |
| 140 | + { |
| 141 | + "cell_type": "code", |
| 142 | + "execution_count": 6, |
| 143 | + "metadata": {}, |
| 144 | + "outputs": [ |
| 145 | + { |
| 146 | + "data": { |
| 147 | + "text/plain": [ |
| 148 | + "DataFrame[Date: timestamp, Open: double, High: double, Low: double, Close: double, Volume: int, Adj Close: double]" |
| 149 | + ] |
| 150 | + }, |
| 151 | + "execution_count": 6, |
| 152 | + "metadata": {}, |
| 153 | + "output_type": "execute_result" |
| 154 | + } |
| 155 | + ], |
| 156 | + "source": [ |
| 157 | + "result = spark1.sql(\"SELECT * FROM stock LIMIT 5\")\n", |
| 158 | + "result" |
| 159 | + ] |
| 160 | + }, |
| 161 | + { |
| 162 | + "cell_type": "code", |
| 163 | + "execution_count": 8, |
| 164 | + "metadata": {}, |
| 165 | + "outputs": [ |
| 166 | + { |
| 167 | + "data": { |
| 168 | + "text/plain": [ |
| 169 | + "['Date', 'Open', 'High', 'Low', 'Close', 'Volume', 'Adj Close']" |
| 170 | + ] |
| 171 | + }, |
| 172 | + "execution_count": 8, |
| 173 | + "metadata": {}, |
| 174 | + "output_type": "execute_result" |
| 175 | + } |
| 176 | + ], |
| 177 | + "source": [ |
| 178 | + "result.columns" |
| 179 | + ] |
| 180 | + }, |
| 181 | + { |
| 182 | + "cell_type": "code", |
| 183 | + "execution_count": 9, |
| 184 | + "metadata": {}, |
| 185 | + "outputs": [ |
| 186 | + { |
| 187 | + "name": "stdout", |
| 188 | + "output_type": "stream", |
| 189 | + "text": [ |
| 190 | + "+-------------------+----------+----------+------------------+------------------+---------+------------------+\n", |
| 191 | + "| Date| Open| High| Low| Close| Volume| Adj Close|\n", |
| 192 | + "+-------------------+----------+----------+------------------+------------------+---------+------------------+\n", |
| 193 | + "|2010-01-04 00:00:00|213.429998|214.499996|212.38000099999996| 214.009998|123432400| 27.727039|\n", |
| 194 | + "|2010-01-05 00:00:00|214.599998|215.589994| 213.249994| 214.379993|150476200|27.774976000000002|\n", |
| 195 | + "|2010-01-06 00:00:00|214.379993| 215.23| 210.750004| 210.969995|138040000|27.333178000000004|\n", |
| 196 | + "|2010-01-07 00:00:00| 211.75|212.000006| 209.050005| 210.58|119282800| 27.28265|\n", |
| 197 | + "|2010-01-08 00:00:00|210.299994|212.000006|209.06000500000002|211.98000499999998|111902700| 27.464034|\n", |
| 198 | + "+-------------------+----------+----------+------------------+------------------+---------+------------------+\n", |
| 199 | + "\n" |
| 200 | + ] |
| 201 | + } |
| 202 | + ], |
| 203 | + "source": [ |
| 204 | + "result.show()" |
| 205 | + ] |
| 206 | + }, |
| 207 | + { |
| 208 | + "cell_type": "markdown", |
| 209 | + "metadata": {}, |
| 210 | + "source": [ |
| 211 | + "### Run a slightly more complex query\n", |
| 212 | + "How many entries in the `Close` field are higher than 500?" |
| 213 | + ] |
| 214 | + }, |
| 215 | + { |
| 216 | + "cell_type": "code", |
| 217 | + "execution_count": 22, |
| 218 | + "metadata": {}, |
| 219 | + "outputs": [ |
| 220 | + { |
| 221 | + "name": "stdout", |
| 222 | + "output_type": "stream", |
| 223 | + "text": [ |
| 224 | + "+------------+\n", |
| 225 | + "|count(Close)|\n", |
| 226 | + "+------------+\n", |
| 227 | + "| 403|\n", |
| 228 | + "+------------+\n", |
| 229 | + "\n" |
| 230 | + ] |
| 231 | + } |
| 232 | + ], |
| 233 | + "source": [ |
| 234 | + "count_greater_500 = spark1.sql(\"SELECT COUNT(Close) FROM stock WHERE Close > 500\").show()" |
| 235 | + ] |
| 236 | + } |
| 237 | + ], |
| 238 | + "metadata": { |
| 239 | + "kernelspec": { |
| 240 | + "display_name": "Python 3", |
| 241 | + "language": "python", |
| 242 | + "name": "python3" |
| 243 | + }, |
| 244 | + "language_info": { |
| 245 | + "codemirror_mode": { |
| 246 | + "name": "ipython", |
| 247 | + "version": 3 |
| 248 | + }, |
| 249 | + "file_extension": ".py", |
| 250 | + "mimetype": "text/x-python", |
| 251 | + "name": "python", |
| 252 | + "nbconvert_exporter": "python", |
| 253 | + "pygments_lexer": "ipython3", |
| 254 | + "version": "3.6.8" |
| 255 | + } |
| 256 | + }, |
| 257 | + "nbformat": 4, |
| 258 | + "nbformat_minor": 2 |
| 259 | +} |
0 commit comments